
资料下载


×
一种语义规则为指导的增量优化方法
消耗积分:2 |
格式:rar |
大小:2.81 MB |
2017-12-27
分享资料个
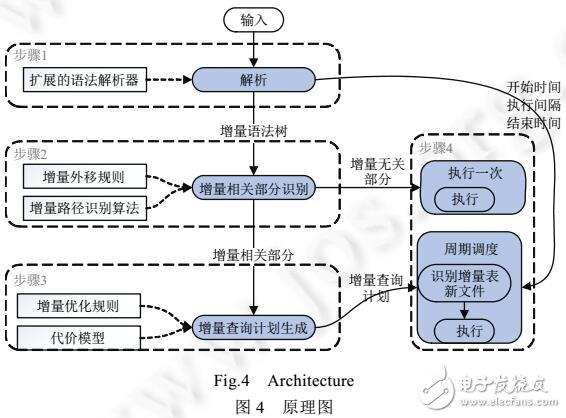
大数据蕴含着巨大的价值.分析类查询是获取数据价值的一种重要手段.为及时把握分析结果的变化。查询需要周期性地重复.为此,将不可避免地引入对旧数据的重复分析.目前,以重用历史数据的中间结果、优化冗余计算为核心思路的增量分析技术。存在用户透明性不佳、对历史结果存储位置的选择不够智能化等问题,对周期性增量查询的优化效果有限,从兼顾用户透明性和优化收益的角度出发。设计了一种以语义规则为指导的增量优化方法.该方法扩展了增量描述语法,以查询操作符的操作语义和输出语义指导对历史数据存储、合并位置的选择,再根据代价模型和物理查询任务的划分位置对选择结果进行调整,生成优化后可以在分布式计算框架(如MapReduce)周期性调度执行的物理查询任务.以Apache Hive为基础,实现了上述方法的原型Hivelnc.实验结果表明:对于扩展了增量语法描述的TPC-H测试集,Hivelnc相对于优化前可以获得平均2.93倍、最高5.78倍的加速:与经典的优化技术IncMR、Dryadlnc相比,分别可以获得1.69倍和1.61倍的加速.
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章


下载排行榜
- 暂无相关数据

