
资料下载


×
基于元组水平对数据源进行分层抽样
消耗积分:1 |
格式:rar |
大小:2.01 MB |
2017-12-29
分享资料个
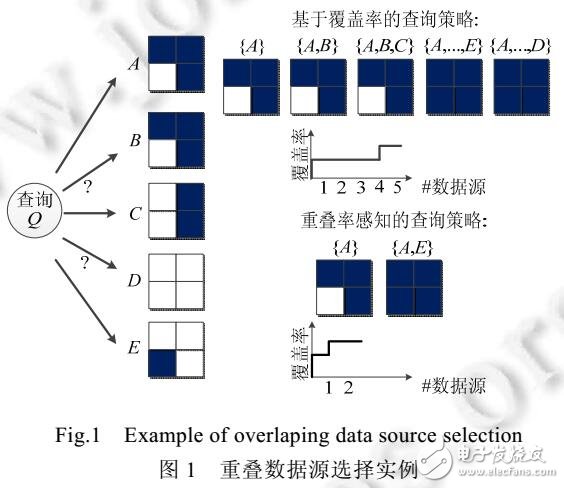
深网查询在Web上众多的应用,需要查询大量的数据源才能获得足够的数据,如多媒体数据搜索、团购网站信息聚合等.应用的成功,取决于查询多数据源的效率和效果,当前研究侧重查询与数据源的相关性而忽略数据源之间的重叠关系,使得不同数据源上相同结果的数据被重复查询,增加了查询开销及数据源的工作负载.为了提高深网查询的效率,提出一种元组水平的分层抽样方法来估计和利用查询在数据源上的统计数据,选择高相关、低重叠的数据源.该方法分为两个阶段:离线阶段,基于元组水平对数据源进行分层抽样,获得样本数据:在线阶段,基于样本数据迭代地估计查询在数据源上的覆盖率和重叠率,并采用一种启发式策略以高效地发现低重叠的数据源.实验结果表明,该方法能够显著提高重叠数据源选择的精度和效率.
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章




