NVIDIA DGX Spark系统恢复过程与步骤
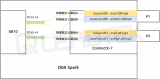
在NVIDIA DGX Spark平台上对NVIDIA ConnectX-7 200G网卡配置教程
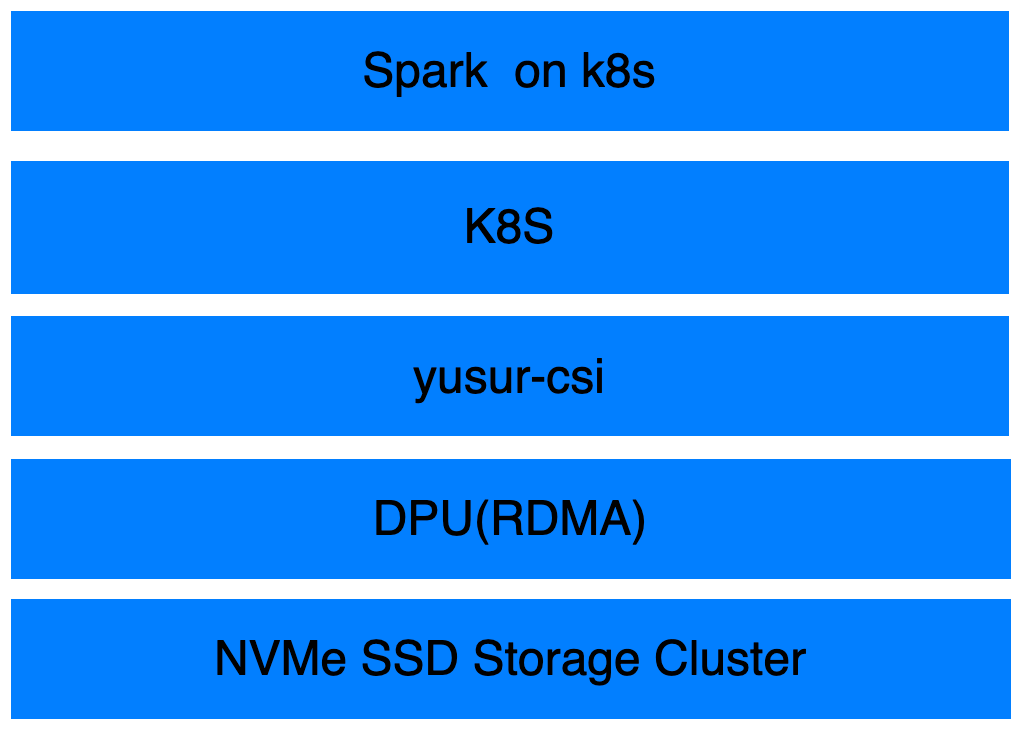
基于DPU云盘挂载的Spark优化解决方案
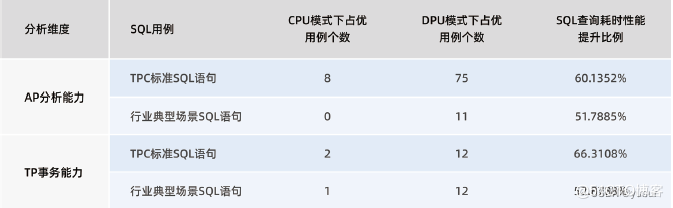
“Spark+Hive”在DPU环境下的性能测评 | OLAP数据库引擎选型白皮书(24版)DPU部分节选
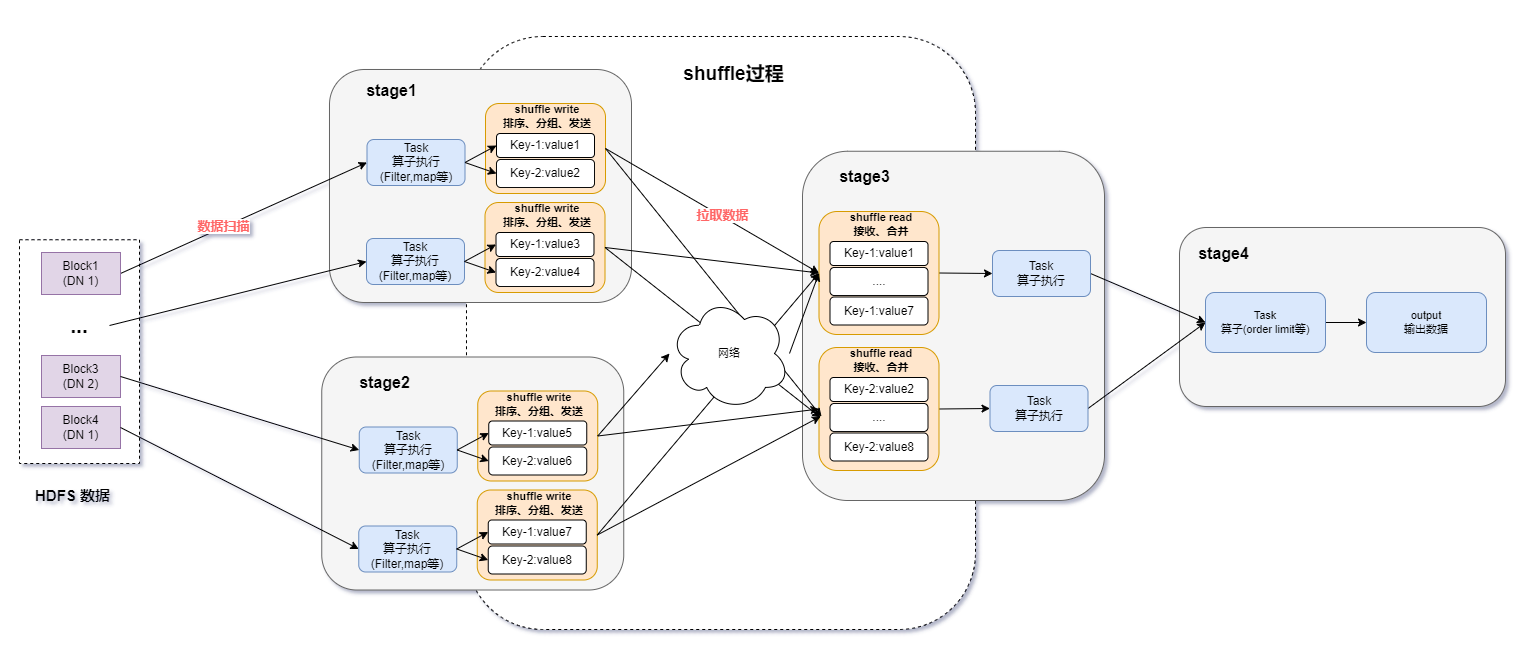
如何利用DPU加速Spark大数据处理? | 总结篇

RDMA技术在Apache Spark中的应用
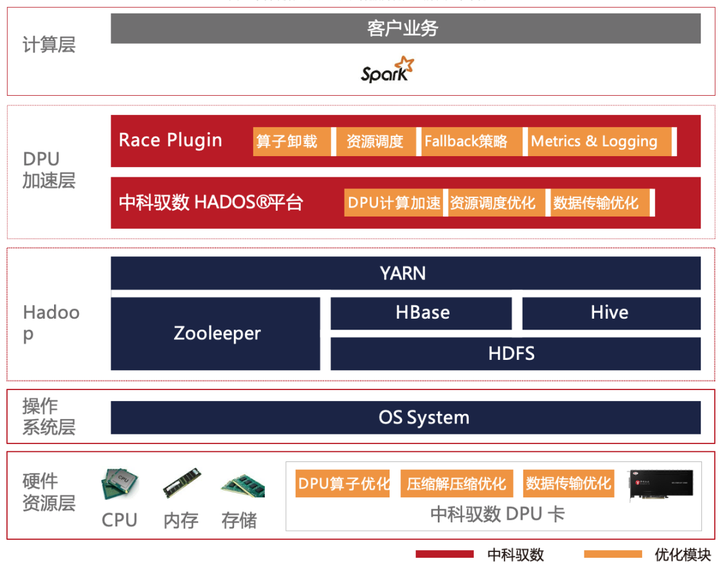
基于DPU和HADOS-RACE加速Spark 3.x

Blaze: 用Rust重写Spark执行层,平均提升30%算力
分析Hive与Spark分区策略的异同点
MapReduce和Spark概要介绍
浅析数据优势
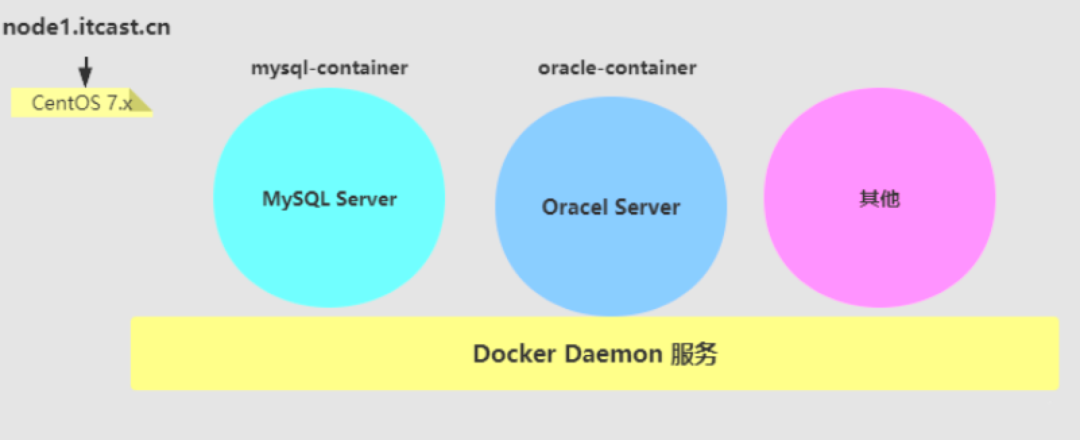
Docker入门指南之Docker使用场景介绍
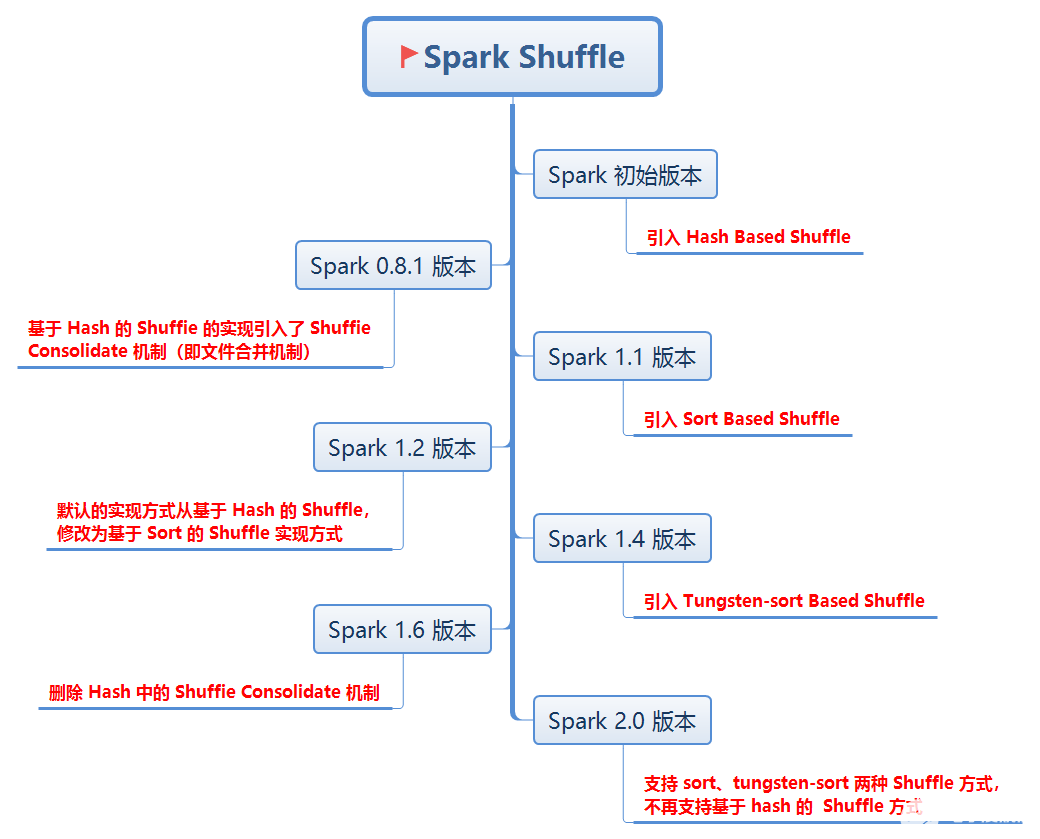
Spark的两种核心Shuffle详解
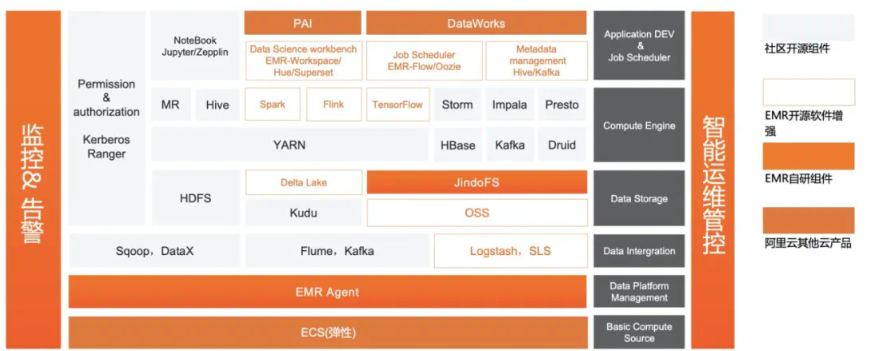
关于Spark on Kubernetes实现方案
大数据分析中Spark,Hadoop,Hive框架该用哪种开源分布式系统
来看看Spark和Flink各自的优劣和主要区别
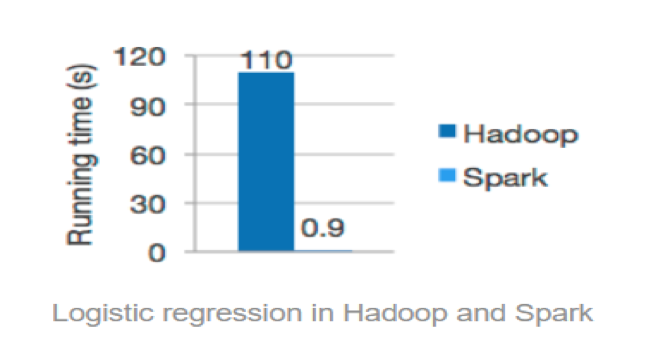
工业大数据挖掘的利器——Spark MLlib
基于Intel Analytics Zoo上分布式TensorFlow的美的/KUKA工业检测平台
宝信利用Spark Analytics Zoo对基于LSTM的时间序列异常检测的探索
Spark和Flink的技术与场景进行全面分析与对比

 下载APP
下载APP
 搜索内容
搜索内容