
资料下载


基于ADE20K构建沉浸式区域图像分割
陈文博
分享资料个
描述
ADE20K 涵盖了场景、对象、对象部分的各种注释,在某些情况下甚至是部分的部分。有 25k 张复杂日常场景的图像,其中包含自然空间环境中的各种对象。每个图像平均有 19.5 个实例和 10.5 个对象类。基于 ADE20K,我们构建了场景解析和实例分割的基准。
视觉场景的语义理解是计算机视觉的圣杯之一。ImageNet、COCO 和 Places 等大规模图像数据集的出现,以及深度卷积神经网络 (CNN) 方法的快速发展,为视觉场景理解带来了巨大进步。
给定客厅的视觉场景,配备训练有素的 CNN 的机器人可以准确预测场景类别。然而,为了在场景中自由导航并操纵里面的物体,机器人需要从输入图像中消化更多的信息:它不仅要识别和定位沙发、桌子、杯子和电视等物体,还要识别和定位它们的位置。部分,例如沙发的座椅或杯子的把手,以允许正确操作,以及分割地板、墙壁和天花板等物品以进行空间导航。
使用 OpenVINO 工具包
初始化 OpenVINO 环境

OpenVINO 的模型优化器首先用于生成模型(.onnx)的 IR(中间表示)文件(.bin 和 .xml)。然后部署模型。
Model Optimizer是一个跨平台的命令行工具,可促进训练和部署环境之间的转换,执行静态模型分析,并调整深度学习模型以在端点目标设备上实现最佳执行。模型优化器过程假设您拥有使用受支持的深度学习框架训练的网络模型。
模型优化器生成网络的中间表示 (IR) ,可以使用推理引擎读取、加载和推断。
生成 IR 文件
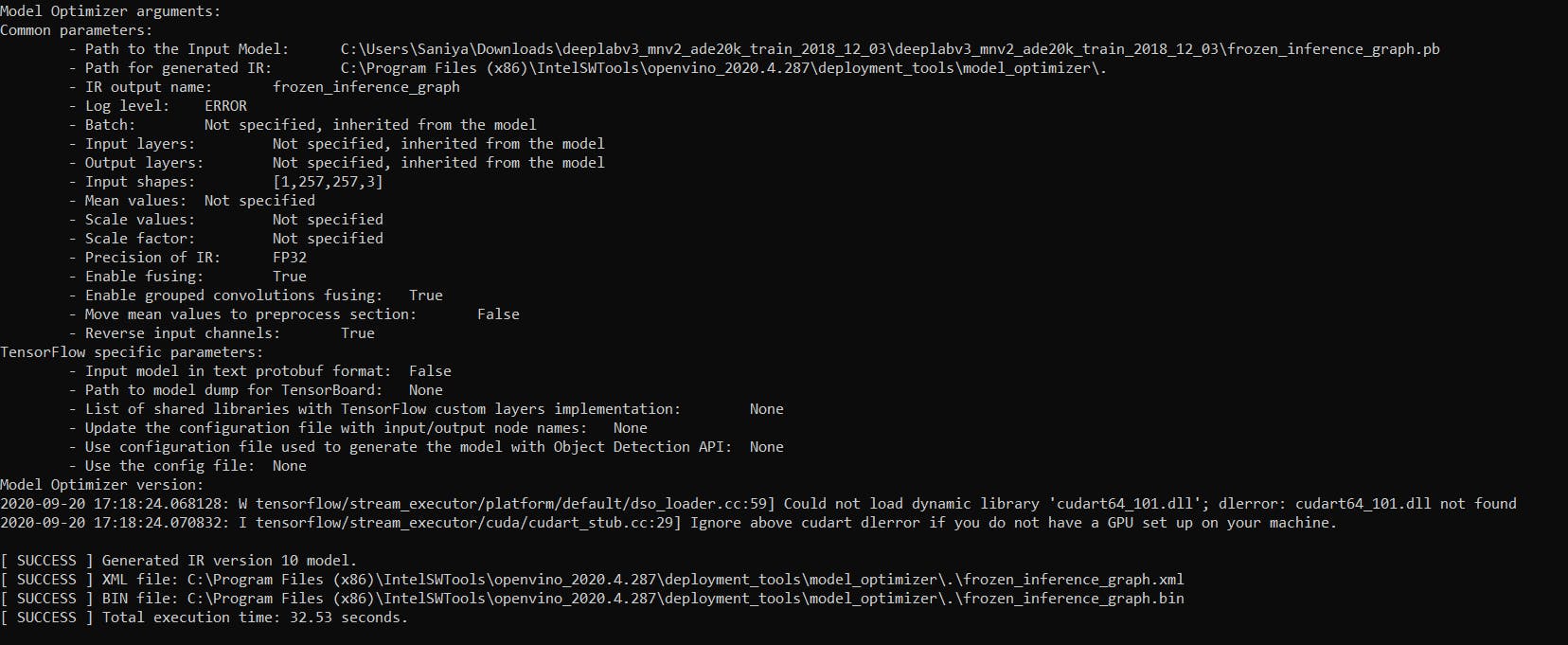
.xml和.bin类型的文件是从模型优化器中获得的。
街景分割
大学走廊分割

使用 OpenVINO工具包 - 基准应用程序
基准工具用于估计深度学习干扰性能。可以针对两种推理模式测量性能:
1)同步(面向延迟)
2)异步(面向吞吐量)
更改了各种参数,并对基准工具进行了观察。
下图给出了在 CPU、GPU 和两种模式下测试的所有参数及其值的列表。
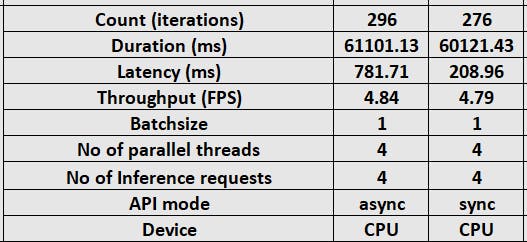
基准工具输出的快照

未来范围
- ADE20K 型号在医疗行业有应用。随着机器人手术数量的增加,可以结合该模型来提高手术的效率和准确性。
- 该模型还可以被用于家庭清洁目的的各种机器人使用,从而提高其操作效率。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章




