
资料下载


基于LDA模型的句子主题特征
分享资料个
随着移动互联网的广泛应用,信息数量激增,用户面临信息过载问题。受到移动终端的屏幕大小和连接带宽大小等限制,推送给用户的新闻通常首先要做摘要处理。按照摘要产生方法的不同自动摘要可以分为抽取式摘要(extractive)和理解式摘要(abstractive)。抽取式摘要直接从原文中抽取重要的句子作为摘要句,而理解式摘要则通过对文章进行句法、语义和篇章结构的分析获取文档的意义,再通过自然语言生成得到满足要求的摘要。
基于LDAl4J (Latent Dirichlet Allocation)的抽取式摘要是近期的研究热点。Shafieic5]提出一种由词、片段、主题、文档四层结构组成的Co-Clustering Model模型,该方法受限于摘要长度,并不是所有从主题类中选出的句子都能作为摘要内容,使得产生的摘要内容代表性不强。Haghighi将句子、文档和文档集合统一纳入到一个层次性LDA主题模型中,使用Gibbs抽样获得模型参数,以KL-散度作为摘要评价模型选择句子,使用贪心算法添加句子。Arora等使用LDA作为文档的表示模型,提出了基于推论的、半生成性和全生成性的3种句子选择形式。该方法仅仅通过计算句子的主题概率来选择摘要句子,忽略了其他常用特征,使得选出的摘要质量不高。
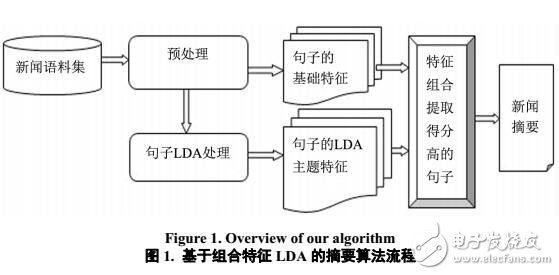
鉴于以上几种方法的缺点,本文提出一种基于LDA模型的句子主题特征,以句子作为处理单元,根据LDA模型中主题的概率分布和句子的概率分布计算文档与句子的主题相似性,并融合句子在文档中的位置和标题相似性等基础特征,形成组合特征共同评价句子的重要性,最后根据融合特征分值大小抽取句子生成摘要。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章



