
资料下载


ThunderGP:基于HLS的FPGA图形处理框架
李义坤
分享资料个
描述
“整个互联网电子商务世界都是由图分析驱动的”,因为图结构可以自然地代表许多重要应用领域的数据集,例如社交网络、网络安全和机器学习。来自这些应用程序的数据对高性能图形处理提出了迫切的需求。
大量研究构建基于 FPGA 的高效图形处理加速器;但是,高级图形应用程序与底层 CPU-FPGA 平台之间仍然存在差距,这需要开发人员了解硬件细节并进行大量编程(例如,使用硬件描述语言进行编程、调整管道和进行内存优化) . 这一差距在很大程度上阻碍了数据中心应用程序开发人员采用 FPGA。
ThunderGP 有什么大不了的?
ThunderGP 通过为 FPGA 加速图形处理带来性能和可编程性来弥补上述差距,并已在FPGA'21中被接受。
ThunderGP 是 FPGA 上基于 HLS 的开源图形处理框架,支持 Vitis 和 SDAccel 开发环境,适用于 Xilinx Alveo 平台,如 U50、U200、U250 和 VCU1525。使用 ThunderGP,开发人员只需要编写使用基于显式高级语言 (C++) 且与硬件无关的 API 的高级函数。随后,ThunderGP 在具有多个超级逻辑区域 (SLR) 的最先进 FPGA 平台上自动生成高性能加速器并管理加速器的部署。
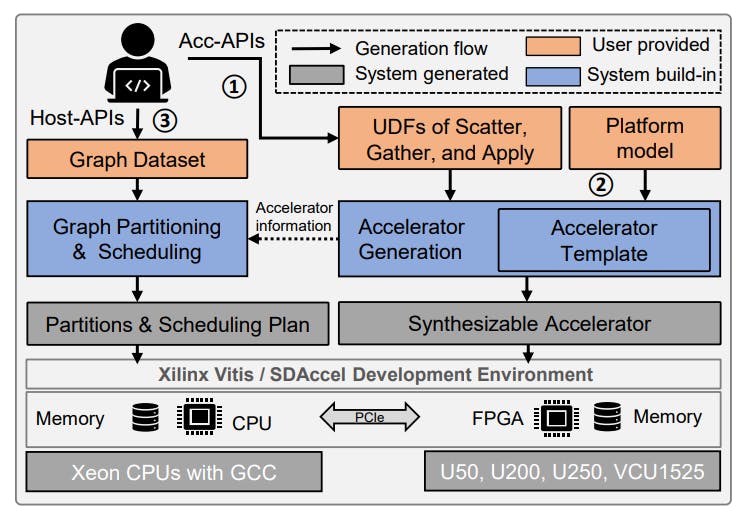
ThunderGP 的概述如图 1 所示。我们简要说明主要构建块如下。
- 内置加速器模板。ThunderGP 采用 Gather-Apply-Scatter (GAS) 模型作为各种图算法的抽象,并通过内置的高并行和内存高效的加速器模板来实现模型。
- 自动加速器生成。自动加速器生成可产生可合成的加速器,释放底层 FPGA 平台的全部潜力。除了内置加速器模板外,它还采用图形算法的分散、聚集和应用阶段(来自 GAS 模型)和 FPGA 平台模型(例如,U50)的用户定义函数 (UDF) ) 来自开发人员作为输入。
- 图分区和调度。ThunderGP 采用基于目标顶点的垂直分区方法,无需引入边缘排序等繁重的预处理操作,即可通过片上 RAM 实现顶点缓冲。
- 高级API。ThunderGP 提供了两组基于 C++ 的 API:用于自定义图形算法加速器的加速器 API (Acc-API) 和用于加速器部署和执行的 Host-API。
有关 GAS 模型、API 和 ThunderGP 设计的详细信息,请参阅ThunderGP 技术报告(附件或GitHub 上)。
ThunderGP 的易用性如何?
我们进行了一个案例研究——使用 Vitis 2020.1 在 Alveo U50 板上进行 COVID-19 的传播预测——以展示 ThunderGP 如何轻松应用于现实生活中的图形处理问题。
及时预测人口水平上随时间变化的感染流行率对于部署适当的封锁措施(例如隔离或社交距离)以减轻病毒传播具有重要作用。当前的传播预测模型一般由空间元胞自动机(CA)和时间易感感染清除(SIR)模型组成,其中单元代表一个居民区(如县)并保持其状态(如感染率)由 SIR 模型根据相邻小区之间的传输进行更新。因此,传播可以表述为一个图处理问题,其中县及其连接由图表示,并且 SIR 通过图中的传播更新。
我们使用 ThunderGP 实现了三个传播模型:CA-SIR [1]、CA-SEIR [2] 和 CA-SAIR [3] 模型。该数据集来自 COVID-19 影响分析平台 [4],包含 3.1K 县和 2.3M 连接。
在这里,我们展示了为清单 1 中的 CA-SAIR 模型实现加速器的示例。对于分散阶段,每个县(一个小区)根据其感染率及其连接强度计算感染率以推送到相邻县它量化了县际流动的数量和频率。对于聚集阶段,该县会累积推到它的所有感染率。在申请阶段,收集到的感染率用于计算感染率。注意apply阶段涉及到很多用户自定义参数(ThunderGP支持apply阶段自定义参数,详见技术报告)。
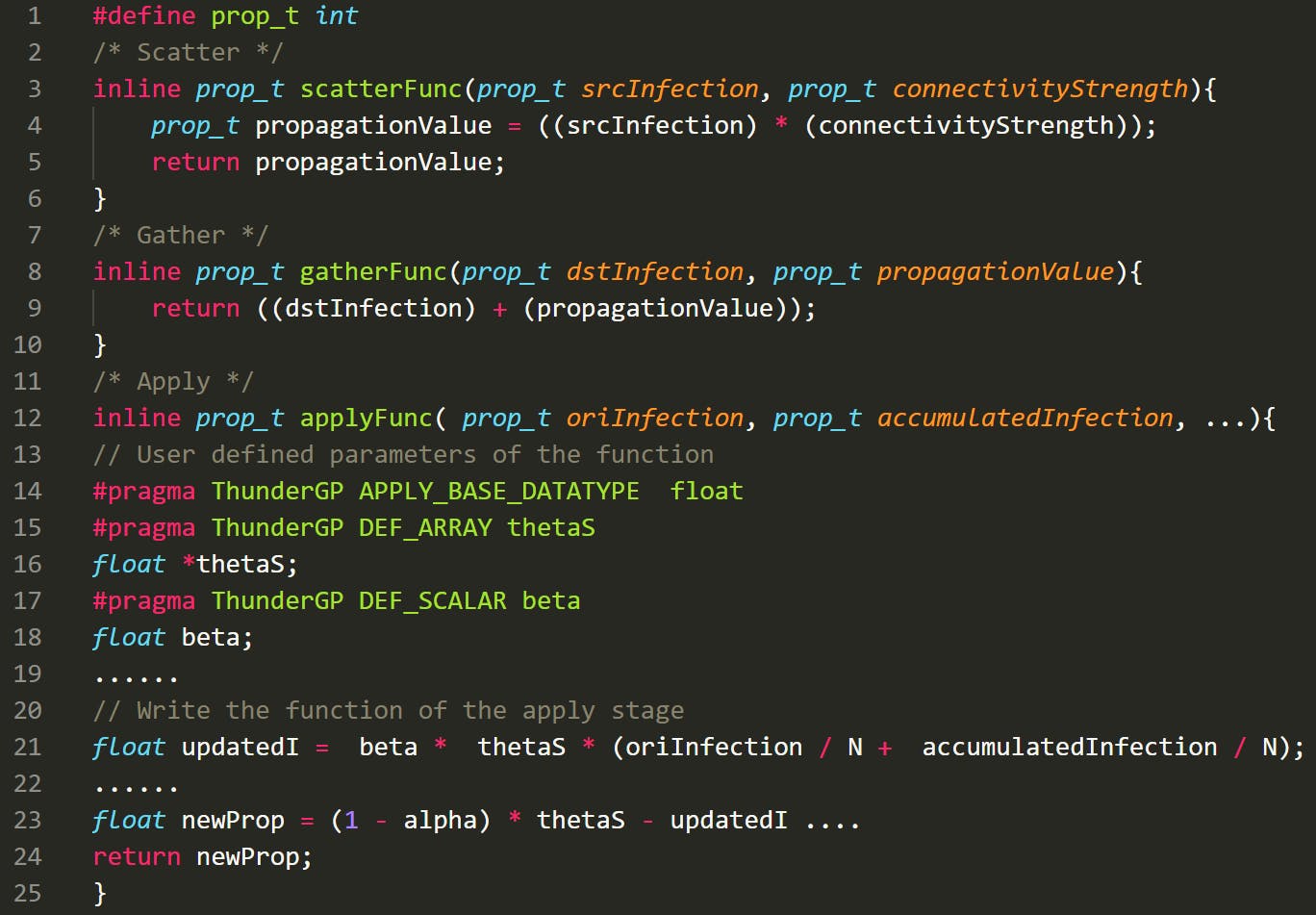
图 2 显示了使用公共数据集进行预测一周后美国感染风险的可视化。结果与在 CPU 端执行的开源 Python 程序 [3] 相匹配。
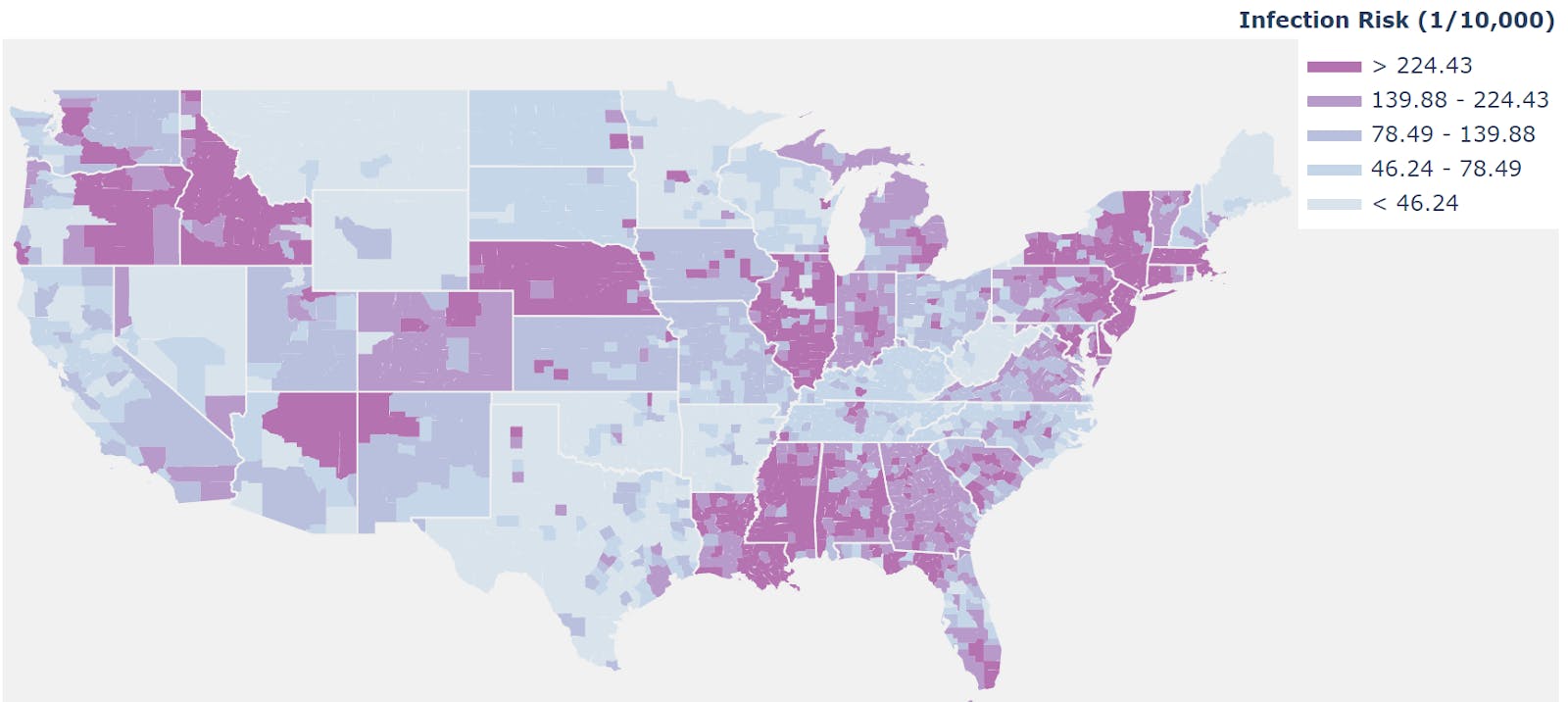
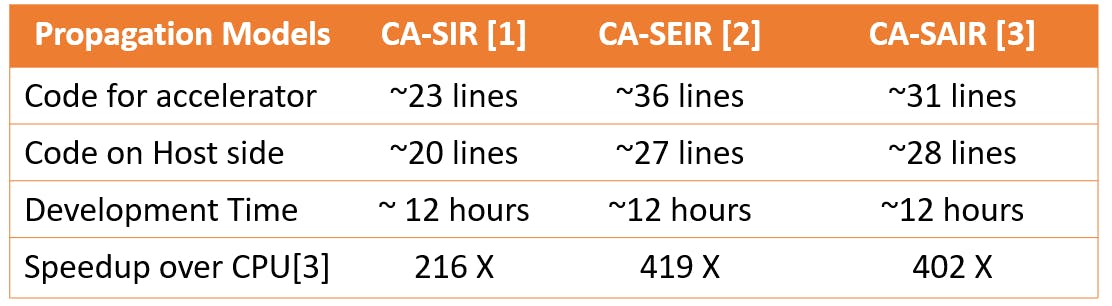
表 1 量化了 ThunderGP 在此任务上所涉及的开发工作,并显示了与基于 Python 的 CPU 实现的性能比较[3]。根据结果,使用 ThunderGP 解决这个问题的好处是双重的。首先,ThunderGP 比基于 CPU 的解决方案实现了高达419 倍的加速。能够在短时间内预测传播可以帮助对传播状况做出快速及时的反应。其次,CA-SIR 模型随着对病毒认识的不断深入而快速发展。使用 ThunderGP,开发者只需编写几十行代码用于加速预测通常一天,这最大限度地减少了开发工作。这个初步结果是有希望的,并且系统是开源的,我们相信可以进行更多的案例研究来进一步评估可编程性的改进。
[1] 马富恩特斯等人。物理学 A:统计力学及其应用,1999。
[2] 何塞 M Carcione 等人。基于确定性 seir 模型的 covid-19 流行病模拟。arXiv,2020 年。
[3] 周一望等。用于告知美国县级 covid-19 风险的时空流行病学预测模型。哈佛数据科学评论,2020 年。
[4] 马里兰大学 COVID-19 影响分析平台。https: //data.covid.umd.edu,2020-09-10。
ThunderGP 的效率如何?
如前所述,已有大量基于 FPGA 的图形处理加速器的研究工作。在本章中,我们将与最先进的设计进行公平比较,以展示 ThunderGP 的效率。数据集和图应用请参考ThunderGP 技术报告。
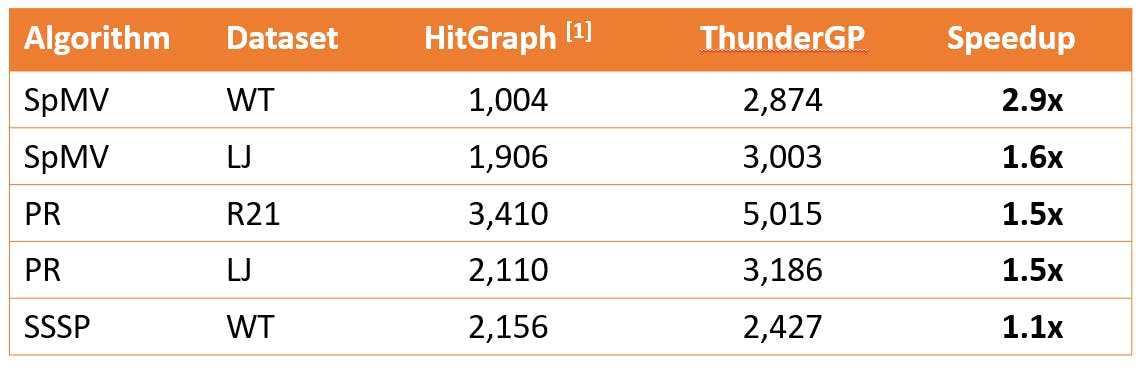
我们首先将 ThunderGP 与最先进的基于 RTL 的工作:Hitgraph [1] 进行比较,如表 2 所示。性能指标是每秒百万边缘遍历 (MTEPS)。所有的实现都基于四个 SLR,但不同之处在于 HitGraph 没有考虑使用多个 SLR 的开销,因为它的性能是基于模拟的,只是简单地缩放到多个 SLR 的内存带宽。性能加速高达 2.9 倍。更重要的是我们让设计在真实硬件上执行。
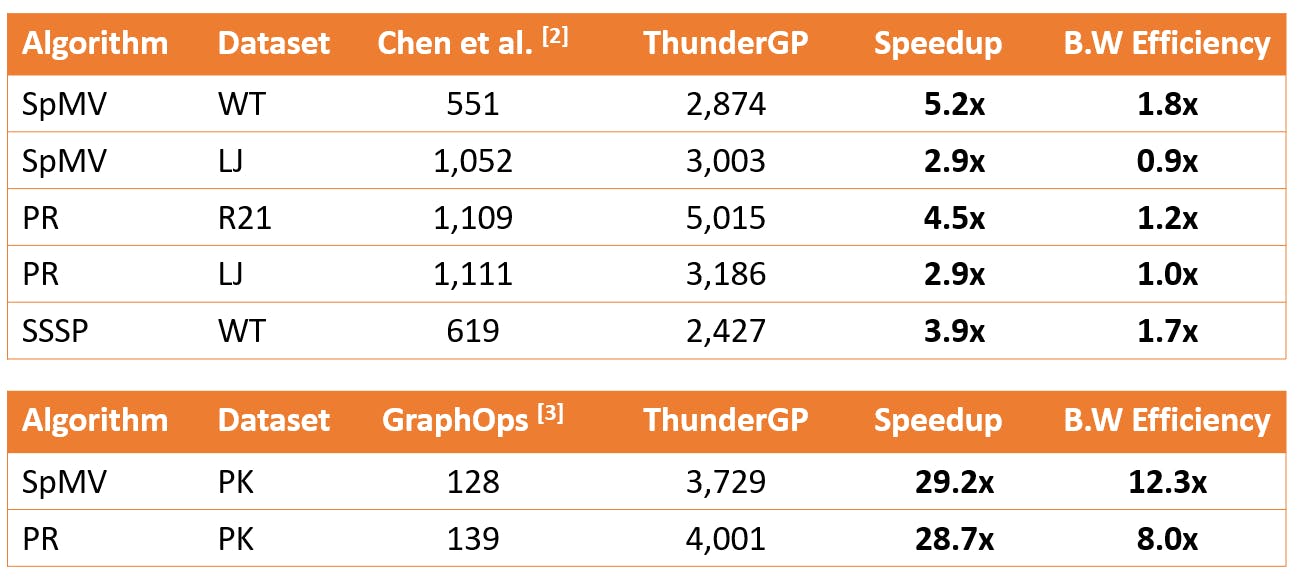
然后我们将 ThunderGP 与基于 HLS 的框架进行比较:Chen 等人。[2] 和 GraphOps[3]。由于他们的实验不是使用多个 SLR 进行的,因此内存带宽较少,为了进行公平比较,我们使用带宽效率 (MTEPS/(GB/s)) 作为衡量标准。如表 3 所示,ThunderGP 比 GraphOps 实现了高达 29.2 倍的绝对加速和 12.3 倍的带宽效率提升,比 Chen 等人实现了 5.2 倍的绝对加速和 2.4 倍的带宽效率提升。
加速来自 ThunderGP 的先进设计。请查看技术报告了解更多设计细节。
[ 1 ]周世杰等.HitGraph:FPGA 上的高吞吐量图处理框架。TPDS,2019 年。
[2] 陈新宇等。用于在基于 opencl 的 fpgas 上进行图形处理的动态并行数据混洗。FPL,2019
[3] Tayo Oguntebi 等人。Graphops:用于图形分析加速的数据流库。FPGA,2016 年。
让我们开始使用 ThunderGP!
到目前为止,您可能对 ThunderGP 感兴趣!
不用担心,我们在 GitHub 存储库中提供了使用 ThunderGP 的分步指南。
对于第一级使用,我们为只需要内置图形处理算法的用户编写指南。
对于二级使用,我们引导用户使用系统提供的API为自己的应用定制加速器。
查看 README https://github.com/Xtra-Computing/ThunderGP/tree/develop_u50 中的详细说明。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章




