
资料下载


基于DeepSORT YOLOv4的目标跟踪
贾小龙
分享资料个
描述
基于 DeepSORT YOLOv4 的目标跟踪
随着道路上的汽车、卡车和不同车辆的数量不断增加,交通拥堵问题仍在日益严重。适当的红绿灯控制可以减少交通并提高十字路口的通行能力,而十字路口往往是交通瓶颈。由于持续监控十字路口的高成本和这项任务的基础设施,更好的方法是使用无人机,它可以监控、跟踪和通知车辆的数量和通过十字路口所需的时间。它可以更好地管理交通信号灯,尤其是在高峰时段或道路整修期间。对于此任务,需要实时对象跟踪算法来持续提供返回结果。所以该项目包含DeepSORT的实现基于 YOLOv4 检测的目标跟踪算法,确保实时响应。检测器推理类在 TensorFlow、TensorFlow Lite、TensorRT、OpenCV 和 OpenVINO 等多个框架中实现,以便对方法进行基准测试并将最佳方法用于边缘定制解决方案。
步骤 0:多对象跟踪简介
MOT 算法作为当前计算机视觉研究的相关部分,与自动驾驶和转向、监视和行为分析有关。MOT 问题主要分为多个子任务,例如检测多个对象(定位和分类)、添加和保持它们的身份,以及在连续帧中跟踪它们的个体轨迹。
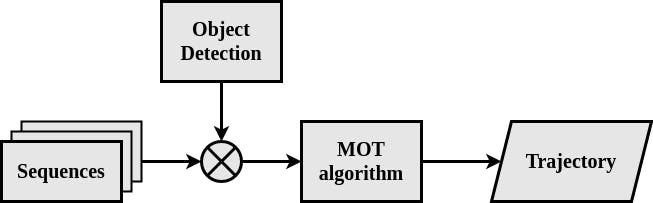
DeepSORT 算法是一种基于检测器的方法,它使用具有恒定运动速率的递归卡尔曼滤波器和线性观察模型。重新识别任务使用匈牙利算法解决。为了提高分配算法的投影和性能,使用了加权度量,包括马氏距离和余弦距离。第一个度量通过计算预测的卡尔曼状态和新到达的测量值之间的距离来提供运动信息。第二个指标使用预训练的深度卷积网络作为图像特征描述符来提供外观信息。
第 1 步:准备检测算法
作为目标检测器,由于其令人满意的结果和实时处理速度,选择了YOLOv4算法。神经网络模型使用Darknet框架和VisDrone 数据集进行训练,其中包含从无人机视角捕获的图像。每个独立对象都属于 11 个类别之一。许多实例的图像的小而被遮挡的部分被标记为忽略区域。
ignored_regions
pedestrian
people
bicycle
car
van
truck
tricycle
awning_tricycle
bus
motor
others
YOLOv4 文件在链接存储库中,配置文件在data/darknet/yolov4_visdrone.cfg中,类文件在data/classes/visdrone.names中,锚框的计算大小在data/anchors/visdrone_anchors.txt中。
第 2 步:边缘设备设置
系统设置。
出于评估目的,使用了NVIDIA Jetson Xavier NX和英特尔神经计算棒 2等边缘设备。Jetson Xavier NX 使用JetPack SDK 4.4.1 刷新,Raspberry Pi 4B 的 SD 卡使用Raspberry Pi OS Lite 5.10刷新。完整的 TensorFlow 库用于 Raspberry Pi 4B,2.2.0 版本的构建指令可在此处获得。
相机设置。
由于使用了 Jetson 相机驱动程序(e-CAM24_CUNX – 彩色全局快门相机),必须使用 4.4.1 版本的 JetPack。e-con Systems 作为制造商提供了适用于 NVIDIA Jetson Nano 和 Xavier NX 的摄像头驱动程序和简单的安装说明。
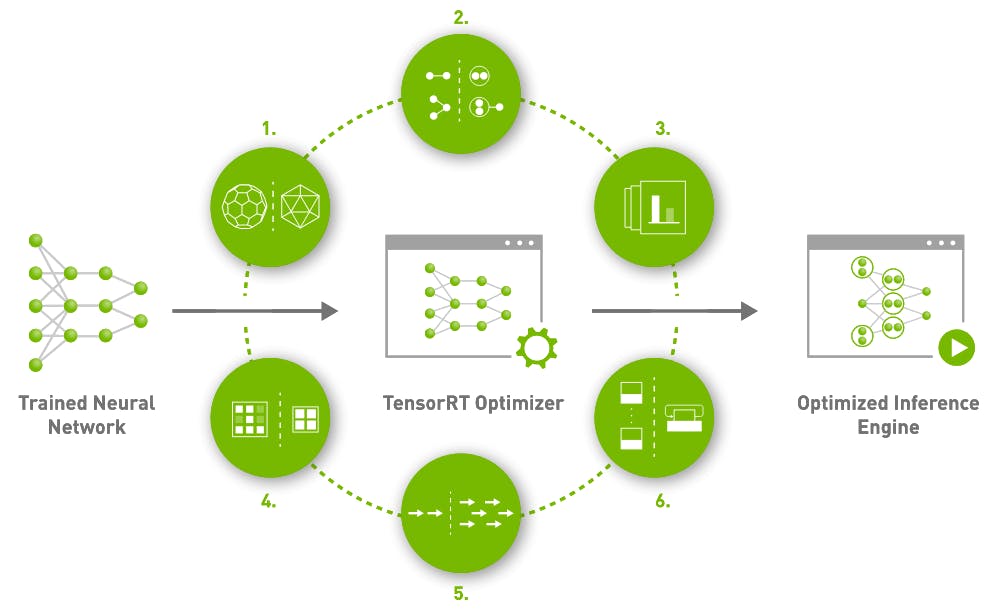
第 3 步:边缘定制的检测器模型优化和量化
使用 NVIDIA Jetson Xavier NX 的TensorRT 、英特尔神经计算棒 2 的 OpenVINO 和基于 CPU 的解决方案的 TensorFlow Lite执行优化和量化过程。
TensorRT框架需要将模型转换为一种受支持的格式,例如 ONNX 或 TensorFlow。在本项目中,使用了对 ONNX 格式的更改。为了将存储库中可用的脚本yolo_to_onnx.py与以下调用一起使用,其中 -c 描述了许多类-m输入模型和-o输出 ONNX 模型路径。
python3 yolo_to_onnx.py -c 12 -m ./yolov4-608 -o ./yolov4.onnx
要将模型从 ONNX 更改为 TensorRT,使用了onnx_to_tensorrt.py脚本。模型的 TensorRT 表示以三种不同的数据类型呈现:FP32 和量化的 FP16 和 INT8。
- 使用 float32 权重将 ONNX 转换为 TensorRT 引擎
python3 onnx_to_tensorrt.py -v -c 12 -m ./yolov4 -q fp32 -o ./yolov4_fp32.trt
- 使用 float16 权重将 ONNX 转换为 TensorRT 引擎
python3 onnx_to_tensorrt.py -v -c 12 -m ./yolov4 -q fp16 -o ./yolov4_fp16.trt
- 将 ONNX 转换为具有 int8 权重的 TensorRT 引擎(需要校准数据集的路径 - 来自数据集的代表性图像,下面标记为“./calib_images” )
python3 onnx_to_tensorrt.py -v -c 12 -m ./yolov4 -i ./calib_images -q int8 -o ./yolov4_int8.trt
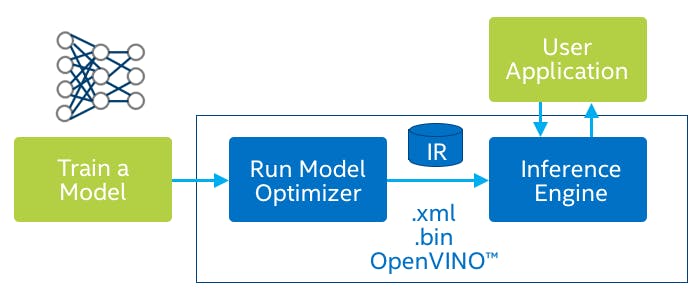
OpenVINO使用了从tensorrt/README.md的指令生成的 ONNX 文件,然后使用 OpenVINO模型优化器包和命令:
- FP32 数据格式:
python3 mo.py --input_model ./yolov4.onnx --model_name yolov4_fp32 --data_type FP32 --batch 1
- FP16 数据格式:
python3 mo.py --input_model ./yolov4.onnx --model_name yolov4_fp16 --data_type FP16 --batch 1
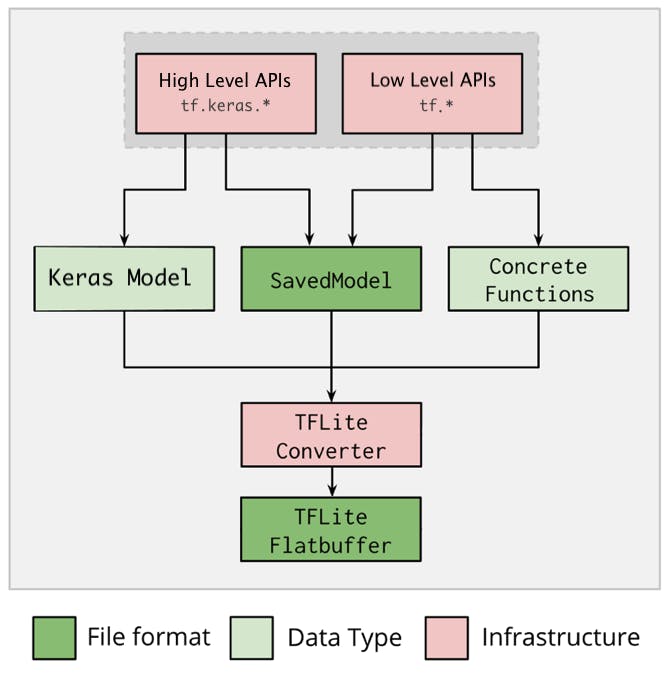
通过命令行界面使用 ONNX 模型和onnx-tensorflow包完成到TensorFlow Lite的转换:
onnx-tf convert -i /path/to/input.onnx -o /path/to/output
它支持从 ONNX 格式更改为 TensorFlow SavedModel 表示。使用内部 TensorFlow TFLiteConverter 可以转换为 TF Lite。
- FP32 格式
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_saved_model(MODEL_PATH)
tflite_model = converter.convert()
# Save the model.
with open(OUTPUT_PATH, 'wb') as f:
f.write(tflite_model)
- FP16 格式
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_saved_model(MODEL_PATH)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.float16]
tflite_model = converter.convert()
# Save the model.
with open(OUTPUT_PATH, 'wb') as f:
f.write(tflite_model)
第 4 步:如何使用 DeepSORT 跟踪器
DeepSORT 算法从 YOLOv4 中获取检测结果,并使用递归卡尔曼滤波器和匈牙利算法将它们关联起来。
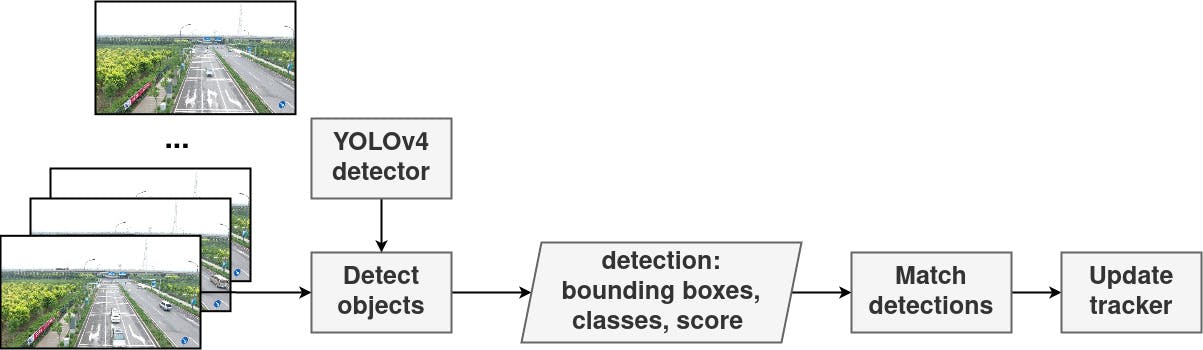
。它是在 NVIDIA Jetson Xavier NX 上使用 TensorRT 在 FP32 模式下执行的。
笔记
如果想要运行推理,一台支持 TensoRT 的 NVIDIA 设备需要取消注释检测器/__init__.py 中的TrtYOLO检测器导入。同样的问题是在英特尔硬件上使用OpenvinoYOLO类。
命令行参数
Usage: object_tracker.py [OPTIONS]
Options:
-f, --framework TEXT Inference framework: {tf, tflite, trt, opencv,
openvino}
-m, --model_path TEXT Path to detection model
-n, --yolo_names TEXT Path to YOLO class names file
-s, --size INTEGER Model input size
-v, --video_path TEXT Path to input video
-o, --output TEXT Path to output, inferenced video
--output_format TEXT Codec used in VideoWriter when saving video to
file
--tiny BOOLEAN If YOLO tiny architecture
--model_type TEXT yolov3 or yolov4
--iou FLOAT IoU threshold
--score_threshold FLOAT Confidence score threshold
--opencv_dnn_target TEXT Precision of OpenCV DNN model
--device TEXT OpenVINO inference device, available: {MYRIAD,
CPU, GPU}
--dont_show BOOLEAN Do not show video output
--info BOOLEAN Show detailed info of tracked objects
--count BOOLEAN Count objects being tracked on screen
--help Show this message and exit.
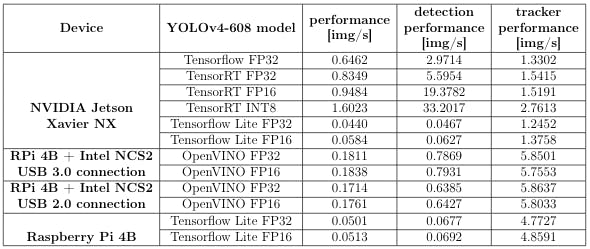
第 5 步:性能测试
基准测试是在NVIDIA Jetson Xavier NX和英特尔神经计算棒 2上执行的。Jetson Xavier NX 处于模式 2 ( sudo nvpmodel -m 2) 和风扇,时钟通过命令设置为最大频率sudo jetson clocks --fan。为了评估英特尔 INCS 2,使用了 Raspberry Pi 4B。评价结果如下所示。
第 6 步:功耗测试
在性能评估期间,检查了基准边缘设备的能效。英特尔神经计算棒 2 和树莓派 4B 的功耗是使用 USB 多功能测试仪测量的,如下图所示。


Jetson Xavier NX 的能源使用情况通过使用旨在监控和控制 NVIDIA Jetson 设备的jetson-stats包进行检查。所进行的测试的结果如下表所示。
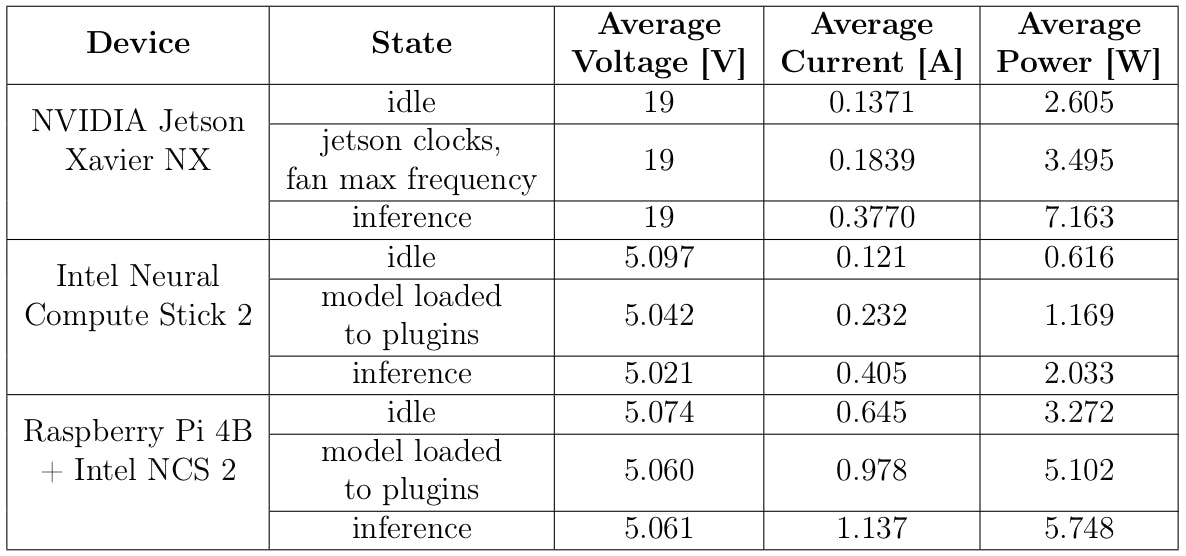
相比之下,NVIDIA V100 或 RTX 3080 等云中心中用于推理和计算的显卡的功耗分别为 300 和 320 瓦,如下所示。
跟踪算法的用例
多对象跟踪的可能用例是:
- 监视监控
- 十字路口流量跟踪
- 不安全场所监测预警
参考
非常感谢您的出色工作:
- 人工智能专家:yolov4-deepsort ,麻省理工学院许可证
- nwojke : deep_sort , MIT 许可证
- jkjung-avt : tensorrt_demos , MIT 许可证
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章





