
资料下载


×
基于SVD的Kmeans聚类协同过滤算法王伟
消耗积分:1 |
格式:pdf |
大小:493KB |
2017-03-08
#Freedom
分享资料个
基于SVD的K_means聚类协同过滤算法_王伟
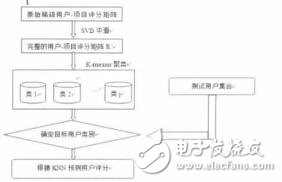
协同过滤技术是目前电子商务推荐系统中最成功和应用最广泛的技术,在理论研究和实践中都取得了快速的发展,它根据用户的历史选择信息和相似性关系, 收集与用户兴趣爱好相同的其他用户的评价信息利用数据挖掘的一些算法来产生推荐。然而,传统的协同过滤算法面临数据稀疏、用户相似性难以度量、实时性和可扩展性差等方面的挑战,影响了推荐系统的质量。针对推荐系统数据稀疏和可扩展性差的问题,许多研究者提出了利用矩阵分解或者降维的方法来解决推荐系统数据稀疏和可扩展性差的问题,如奇异值分解(SVD)、非负矩阵分解(Nonnegative Matrix Factorization, 简称 NMF), 主成分分析(Principal Component Analysis,简称 PCA)等,有效地降低训练数据的维度和稀疏性。本文针对基于内存的协同过滤算法在线计算量较大且可扩展性较低的缺点,提出了一种基于 SVD 矩阵填充技术的 K-means 聚类协同过滤算法。该算法利用用户与项目之间的潜在关系克服了稀疏性问题, 同时保留了聚类方法可离线建模、可扩展性好等优点。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章



