
资料下载


×
基于K近邻特征选择算法的对比分析
消耗积分:0 |
格式:rar |
大小:0.61 MB |
2017-11-06
分享资料个
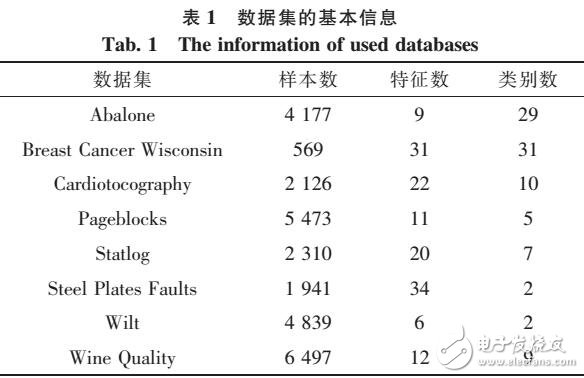
KNN算法的主要分为3步:首先,计算待分类样本与已知类别的训练样本之间的距离或相似度,找到与待分类样本最近的k个样本,称之为待分类样本的k个近邻:其次,根据这些样本所属的类别来判断待分类样本的类别,如果待分类样本的k个近邻都属于同一个类别,那么待分类样本也属于该类别:否则的话,对每一个候选类别进行评分,按照一定的规则来确定待分类样本的类别。
K近邻算法中的分类决策规则往往遵循多数表决,多数表决是指由待分类样本的k个近邻(训练样本)所得到的多数类别来决定输入样本的类别。尽管K近邻算法可以在一定程度上有效地判断出待分类样本的类别,但其结果往往也伴随着误差,这样的误差文中称为近邻错误分类率。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章




下载排行榜
- 暂无相关数据

