
资料下载


×
基于KNN的烟草企业档案文本分类
消耗积分:1 |
格式:rar |
大小:0.40 MB |
2017-12-12
分享资料个
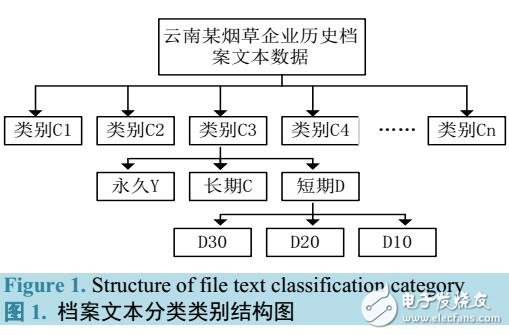
通过对云南某卷烟厂历史档案文本数据的分析研究,结合实际情况,对档案文本主题词的获取和自动分类算法进行了详细的设计。且在主题词获取算法中引入了TFIDF算法,解决了档案文本缺少题名、文号及责任者项时,算法无法自动获取主题词的问题。在文本自动分类算法中引入了KNN最邻近算法,解决了无法根据题名、文号进行档案文本自动分类的问题。同时,还考虑了档案文本按保存期限进行分类的问题。实验结果证明,该算法明显提高了烟草企业档案文本的分类效率。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章



下载排行榜
- 暂无相关数据

