
资料下载


Winnowing指纹串匹配的重复数据删除算法
分享资料个
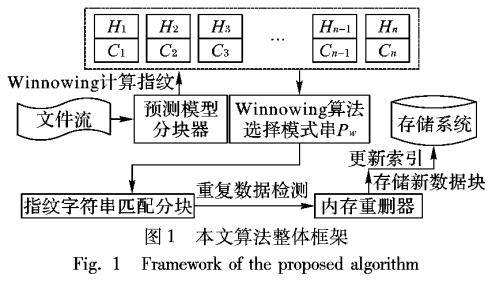
目前数据激增问题使数据中心处理的数据量呈现爆炸式增长,数据存储、备份和恢复所需的时间和容量也随之增大,给存储系统带来了沉重的负担。由于数据来源不同,许多数据被反复存储,造成了大量的数据冗余,尤其在备份系统中更加突出。重复数据删除技术的出现引起了研究者的关注,它不仅能够减少存储和处理的数据量,节约数据的管理和存储成本,同时提高了网络通信的速度,成为降低数据中心冗余数据量的有效手段。
为了在存储系统中充分利用重复数据删除技术,减少数据的最终积累量,缩短消除冗余数据的时间,许多经典的重复数据删除算法被提出。EB( Extreme Binning)算法。利用文件相似性,使用最小块签名作为文件的特征,只在内存中保存文件的代表块ID,有效减小了内存占用。然而,最小块ID作为主索引,一方面重删率相对较低,另一方面数据分块算法影响最小块签名,不同的分块算法所产生的最小块可能不同,从而影响重删的准确性。Bloom filter算法利用K个Hash函数将数据块MD5值映射到m位的向量y中,减少频繁的I/O操作,但存在假正例( False Positives)误识别率,并且无法从Bloom Filter榘合中删除元素,在需要数据修改的场景下不能使用。张沪寅等提出了用户感知的重复数据删除算法,根据用户相关度,以用户为单位,减少了数据空间局部性,但对于非人为产生的数据,其相似性计算准确度较低。
以上算法在数据分块时均采用了可变长度分块( Content-Defined Chunking,CDC)算法,相对于以文件为粒度,数据块级粒度能够检测到文件内部的重复数据,因此,目前大多数重复数据删除算法均采用数据块为粒度。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章


下载排行榜
- 暂无相关数据

