
资料下载


×
基于Spark的动态聚类算法研究
消耗积分:3 |
格式:rar |
大小:3.05 MB |
2017-12-04
分享资料个
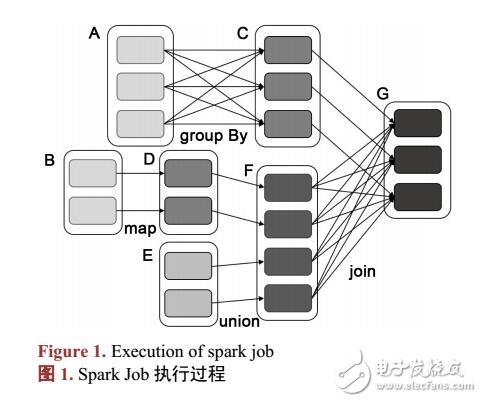
针对数据流的聚类算法,近年来取得了有效的进展,出现了许多卓有成效的算法。随着信息采集技术的进步,需要处理的数据量越来越大,需要研究针对数据流的并行聚类算法。本文基于串行的数据流聚类算法D-Stream作出并行化改进,用通用的大数据处理框架Spark设计了一个基于分布式架构运行的动态数据聚类算法PDStream。实验结果表明,该算法具有更高的效率和良好的扩展性,能够实现分布式架构下的流数据动态聚类。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章


下载排行榜
- 暂无相关数据

