
资料下载


×
大数据处理的优化抽样聚类K-means算法
消耗积分:1 |
格式:rar |
大小:0.86 MB |
2017-12-22
分享资料个
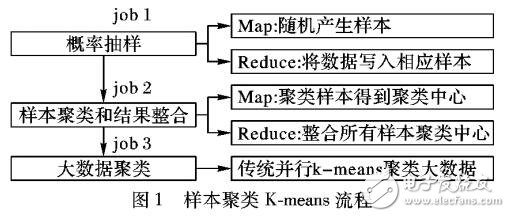
针对大数据环境下K-means聚类算法聚类精度不足和收敛速度慢的问题,提出一种基于优化抽样聚类的K-means算法(OSCK)。首先,该算法从海量数据中概率抽样多个样本;其次,基于最佳聚类中心的欧氏距离相似性原理,建模评估样本聚类结果并去除抽样聚类结果的次优解;最后,加权整合评估得到的聚类结果得到最终五个聚类中心,并将这K个聚类中心作为大数据集聚类中心。理论分析和实验结果表明,OSCK面向海量数据分析相对于对比算法具有更好的聚类精度,并且具有很强的稳健性和可扩展性。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章


下载排行榜
- 暂无相关数据

