
资料下载


×
基于PCA的HK聚类算法研究何莹
消耗积分:1 |
格式:pdf |
大小:655KB |
2017-03-08
#Freedom
分享资料个
基于PCA的H_K聚类算法研究_何莹
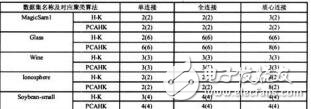
聚类分析作为对数据进行分析的一种重要手段,是根据使得各簇内对象的相似性最大化和簇间对象的相似性最小化的基本原则, 将数据集中的对象划分为紧密而独立的簇集;目前,聚类分析被广泛应用于模式识别、信息检索、机器学习、生物信息学等领域,是数据挖掘中一个非常活跃的研究分支。目前,学术界已经提出了许多不同类型的聚类算法, 主要包括:划分方法、层次方法、基于密度的方法、基于网格的方法和基于模型的方法, 这些方法根据自身的不同特点应用于不同的领域中。其中,k-means 是经典的划分方法,优点是算法简单和收敛速度快, 但是 k 值的预先未知性及初始中心位置选择的随机性都将产生不同的聚类结果, 进而导致结果簇集的不确定性; 而层次聚类算法具有较好的聚类质量, 但是较高的时间复杂度和空间复杂度使得其难应用于大规模的数据集中。鉴于 k-means 方法和层次方法在处理聚类分析问题上的优势和缺陷,Chen Tung-Shou 等人将层次方法和划分方法结合起来, 提出了 H-K 聚类算法(Hierar- chical k-means ),其思想是:首先采取层次聚类算法获取初始信息(如簇数目,初始聚类中心),然后使用 k-means 聚类算法进一步完善聚类过程。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章



