
资料下载


×
基于apiori算法改进的knn文本分类方法
消耗积分:0 |
格式:rar |
大小:0.88 MB |
2017-11-09
分享资料个
随着互联网信息的飞速增长,文本分类变成了一项处理和资质文本信息的关键技术。文本分类技术可用于分类新闻,在互联网上寻找有趣的信息,或者通过超文本去直到用户的搜索,因为手动建立文本分类器是很困难和耗时的,通过实例去学习分类在这方面就很有优势。
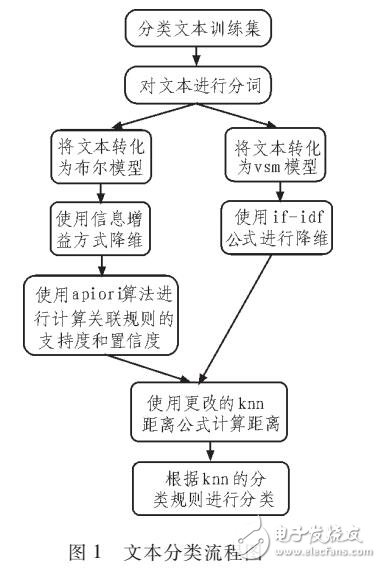
一般的文本分类分为这几个步骤,首先是建立文档的表示模型,即通过若干特征去表示一个文本,因为一般情况下一篇文章都有着成百上千的特征向量,直接进行分类会有很大的时间和空间上的消耗,所以在分类之前,必须先进行特征降维,特征降维的方法主要有信息增益,X2统计,互信息,tf‘-idf等方法,然后就要开始进行分类,常用的一些方法有贝叶斯,knn,支持向量机,关联规则等。其中应用较广的knn等方法中存在受文章长短影响和忽略了语义关联的影响等一些问题。本文针对这些问题结合了apiori算法与knn算法,解决了上述的问题。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章




