
资料下载


×
基于LDA主题模型进行数据源选择方法
消耗积分:2 |
格式:rar |
大小:1.27 MB |
2018-01-04
分享资料个
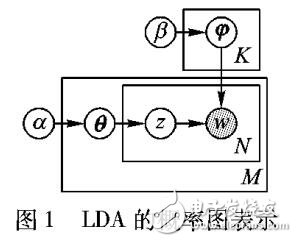
联邦搜索是从大规模深层网上获取信息的一种重要技术。给定一个用户查询,联邦搜索系统需要解决的一个主要问题是数据源选择问题,即从海量数据源中选出一组最有可能返回相关结果的数据源。现有的数据源选择算法大多基于数据源的样本文档集和查询之间的关键词匹配,通常无法很好地解决少量样本文档的信息缺失问题。针对这一问题,提出了基于隐含狄利克雷分布( LDA)主题模型进行数据源选择的方法。首先,使用LDA主题模型获得数据源和查询的主题概率分布;然后,通过比较两者主题概率分布的相近性来对所有数据源进行排序。通过将数据源和查询映射到低维的主题空间来解决高维词条空间稀疏性所带来的信息缺失问题。在TREC FedWeb 2013和2014 Track的测试集上分别进行了实验,并和其他参赛方法的结果进行了比较。在FedWeb 2013测试集上的实验结果显示比其他参赛方法的最好结果提高了24%;在FedWeb 2014测试集上的实验结果显示比传统的基于小文档和大文档的关键词匹配方法分别提高了22%和43%。另外,使用文档片段来代替文档还可以大幅提升系统的效率,更增加了此方法的实用性和可行性。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章



